AWS cost optimization
One of the major challenges in managing large-scale, high-demand computing systems is handling infrastructure costs, especially when system demand fluctuates over time. Traditional infrastructure management typically involves forecasting future demand and acquiring hardware with overestimated capacity to accommodate peak loads. This is due to the lengthy and cumbersome process of hardware acquisition, which can take months and lacks the flexibility to scale quickly. As a result, unnecessary hardware remains idle for extended periods, while in extreme cases, the available infrastructure may fail to support demand, leaving no immediate solution.
Given this scenario, it is essential to evaluate four key factors: the cost of acquiring infrastructure, the cost of its maintenance, the inefficiencies arising from underutilized computing capacity, and finally, the operational costs associated with storage and continuous infrastructure operation. These include energy consumption for power and cooling, rental of appropriate spaces, among others.
A strategic approach to mitigating these cost factors and avoiding wasted computing resources during low-demand periods is adopting cloud infrastructure, a widely used solution today. Various cloud providers, such as AWS, offer a comprehensive range of services, relieving organizations from hardware acquisition, maintenance, and associated expenses. This shifts the primary cost consideration to the provider's pay-as-you-use pricing model, where expenses fluctuate based on system demand.
The key challenge is selecting the most suitable cloud services that align with system requirements while managing associated costs effectively, avoiding unnecessary expenditures on idle computing capacity. This study explores a migration strategy from a traditional cloud-native architecture to a cost-optimized modern architecture.
Context
The project aimed to achieve two main objectives: reducing cloud infrastructure costs while adopting a set of unattended services that would enable a leaner DevOps team to provide support without compromising high availability.
To accomplish these objectives, we structured the project into four phases:
Analysis of current infrastructure/architecture: This phase involved assessing the existing infrastructure and architecture, identifying key components and their interdependencies to determine optimization opportunities.
Select AWS services that allow us simplify maintenance and optimize costs: This step focused on selecting modern AWS services that not only reduced maintenance complexity but also contributed to cost optimization. The goal was to find solutions aligning with project requirements while ensuring efficient management with a smaller team.
System migration: Migration was a critical phase involving the implementation of planned changes. This included transferring data, configurations, and functionalities to the new infrastructure while minimizing system downtime.
Cost control before, during and after migration: Post-migration, we implemented a robust monitoring system to track costs at every stage. This included pre-migration analysis, real-time monitoring during the transition, and post-migration assessment. This approach ensured cost containment within projected limits and allowed for strategy adjustments when necessary.
These four phases were designed to comprehensively address project objectives, ensuring a seamless transition to a more efficient and cost-effective infrastructure.
Analysis of current infrastructure
The systems were hosted on AWS, utilizing a containerized microservices architecture based on Docker. These microservices were deployed on Swarm clusters running on AWS EC2 instances, with classic load balancers at the front end, as illustrated in Figure 1.

Fig. 1 - Example of pre-migration architecture
Our analysis highlighted several key observations. First, the choice of Docker-based microservices was appropriate for the project's general needs, as several services performed long-running tasks, while others required instantaneous execution with no uptime tolerance. However, we identified an opportunity to migrate some components to services that would not maintain continuously active containers but instead generate costs only when in use.
Additionally, we found that Docker Swarm was not the most efficient solution as system complexity increased. As the number and size of clusters grew, maintenance demands escalated exponentially, presenting significant operational challenges.
Moreover, system load varied over time, and the practice of preemptive server scaling resulted in excessive expenses.
In summary, our analysis revealed two primary issues:
1. High maintenance requirements for the existing infrastructure: The system's complexity necessitated a large team for maintenance, leading to substantial operational costs.
2. Excessive costs due to idle resource allocation: The preventive over-scaling approach resulted in unnecessary expenditures, as resources were allocated even when not actively utilized.
Which AWS service do we choose to facilitate maintenance and optimize cost?
After analyzing the existing infrastructure and architecture, our goal was to identify AWS services that would support a microservices-based architecture using Docker while simplifying maintenance and optimizing costs.
When exploring cloud solutions for deploying Docker containers while avoiding direct server maintenance, we carefully considered two fundamental options: AWS Lambda and AWS Fargate. While AWS Lambda proved suitable for certain use cases, we encountered limitations in its applicability, as it could not handle our entire workload. As previously mentioned, some services run long-duration processes that exceed AWS Lambda's maximum execution times. Considering this and aiming for a unified solution within a single set of services, AWS Lambda was deemed unfeasible.
In comparison, AWS Fargate stood out due to its ability to host Docker microservices without requiring constant uptime. This provided the necessary flexibility to dynamically adjust resource allocation based on the specific service demand. AWS Fargate was chosen for its ability to strike an optimal balance between operational efficiency and adaptability, offering a comprehensive solution aligned with our specific requirements.
Additionally, we evaluated Docker orchestrators to manage complex systems with a small team. Two popular alternatives were analyzed:
EKS (Elastic Kubernetes Service):
Advantages:
- Industry standard: EKS follows industry standards as it is based on Kubernetes, which is widely adopted and backed by a strong community. This facilitates interoperability and adoption by teams already familiar with Kubernetes.
- Kubernetes ecosystem: Using EKS grants access to Kubernetes' rich ecosystem of tools and resources, including advanced features such as automated deployments, zero-downtime updates, and autoscaling, essential for dynamic production environments.
Disadvantages:
- Steep learning curve: As it is based on Kubernetes, EKS has a steeper learning curve compared to ECS. Implementing and managing Kubernetes clusters can be complex, especially for teams less experienced with this technology.
- Higher configuration complexity: The initial setup of EKS can be more complicated, requiring node configuration, IAM roles, and other elements to establish and maintain a Kubernetes cluster.
- Associated costs: EKS tends to have higher costs than ECS due to the additional complexity and the need to maintain a Kubernetes cluster. This can be an important consideration for projects with tight budgets.
- Implementation time: Adopting EKS typically takes longer compared to ECS. The configuration and deployment of the Kubernetes cluster can be a lengthier process, potentially affecting the agility of rolling out new applications or services.
ECS (Elastic container service):
Advantages:
- Easy to learn: ECS has a gentler learning curve compared to EKS. Its interface and configuration are more intuitive, making it easier for teams with less experience in container orchestration.
- Native integration with AWS: Since ECS is AWS-native, it integrates seamlessly with other AWS services such as IAM (Identity and Access Management), CloudWatch, and CloudFormation. This simplifies management and monitoring within the AWS ecosystem.
- AWS tooling support: ECS has strong support from AWS infrastructure management tools, including Terraform, SDKs, and CDK, which streamline automation and resource deployment.
- Simple scalability: ECS provides efficient tools for scaling services, making it easy to manage changing demand and adjust capacity quickly and effectively without downtime.
Disadvantages:
- While modern, it is not as widely recognized across the industry.
- Less flexibility for non-standard scenarios: Since ECS is a proprietary AWS solution, it may be less flexible compared to EKS when handling unique scenarios or specific requirements that do not align well with ECS's approach. EKS, being Kubernetes-based, offers greater flexibility and is more adaptable for unconventional use cases or highly customized configurations.
Considering the specific context of our project, we opted for ECS for several strategic and practical reasons. First, ECS offered a smoother learning curve, which was crucial for our teams, especially those less familiar with Kubernetes complexities. Its native integration with AWS, along with support for tools such as Terraform, SDKs, and CDK, significantly simplified the implementation and maintenance of our microservices architecture. Additionally, ECS's simpler and more specific nature aligned well with our workload structure, providing an efficient and direct solution for our current needs. While EKS offers notable advantages, ECS emerged as the most pragmatic and effective choice for our immediate objectives, ensuring a smooth and efficient transition to an optimized cloud container environment.
During the service selection process, we faced specific challenges that guided our strategic decisions. The need to migrate older services that did not comply with organizational best practices was an initial obstacle. To address this, we worked closely with development teams, implementing scheduled changes that ensured a smooth and non-disruptive transition, allowing these services to continue operating within the existing infrastructure.
Additionally, during this process, the importance of migrating our repositories and pipelines to AWS Developer Tools became evident. Performance and cost efficiency were key factors, and centralizing these components within the AWS platform enabled a more integrated and optimized management approach.
This combination of challenges and tactical solutions reinforced the decision to choose ECS over EKS in our migration strategy. ECS, aligned with our current needs and facilitating the transition of legacy services, emerged as the most consistent and efficient option in our journey toward an optimized cloud container architecture.
Below is a diagram illustrating the new infrastructure definition.

Figure 2 - New infrastructure design
Migration of the system
With a clear understanding of the context and the newly selected technologies and tools, we initiated the planning and execution of the migration. We adopted a gradual migration strategy, starting with repository and pipeline migrations, followed by integrating lower environments with the new pipelines. Then, we tested and deprecated the infrastructure of these environments, progressively moving towards production.
While effective, this gradual strategy had the drawback of keeping the system duplicated in parts throughout the process, leading to additional costs. This was evident in the existence of a development cluster within the previous infrastructure and a new cluster where the DevOps team operated. This cautious approach was taken to avoid disrupting development teams and, most importantly, to ensure the availability of the production environment.
The entire migration process took considerable time, involving the creation of four environments (DEV/QA/PRE/PROD), each consisting of a significant number of services. Special attention was given to thoroughly testing and validating each environment before proceeding to the next phase. Finally, the transition was completed by reassigning the DNS to the new environment.
This meticulous, step-by-step approach ensured system stability throughout the transition, minimizing disruptions and mitigating associated risks.
Cost monitoring: before, during, and after the migration
To ensure effective financial management and assess the economic impact of the migration, we implemented a comprehensive cost monitoring process at each project stage. This proactive approach provided a complete view of infrastructure expenses, offering critical insights that informed our strategic decisions.
Before the migration: Before starting the migration, we conducted a detailed cost analysis. We identified spending patterns, optimization areas, and potential savings. This preparatory phase provided a crucial baseline for evaluating any cost changes during and after migration.
During the migration: Throughout the project execution, we implemented real-time cost monitoring. We closely tracked spending trends as new services were deployed and infrastructure adjustments were made. This continuous oversight allowed us to promptly address any budget deviations and adjust strategies as necessary to ensure economic efficiency.
After the migration: Once the migration was completed, cost monitoring continued. We evaluated financial performance in the new environment, comparing it to the baseline established before migration. We analyzed long-term trends, identified further optimization opportunities, and ensured that costs remained aligned with business objectives.
This comprehensive cost monitoring approach significantly enhanced the project's financial transparency, ensuring that expected efficiency and savings benefits were realized over time.
Cost evolution
To track costs, we focused on seven services that accounted for 80% of total expenses:
EC2
Elastic Load Balancing
Elastic Container Service (Fargate)
CloudWatch
Virtual Private Cloud
Backup
Simple Storage Service (S3)
It is important to clarify that the AWS account where the migration tasks were performed also contains other external systems unrelated to the project, which were ignored in this cost analysis.


Tab. 1 - Cost Evolution by Service
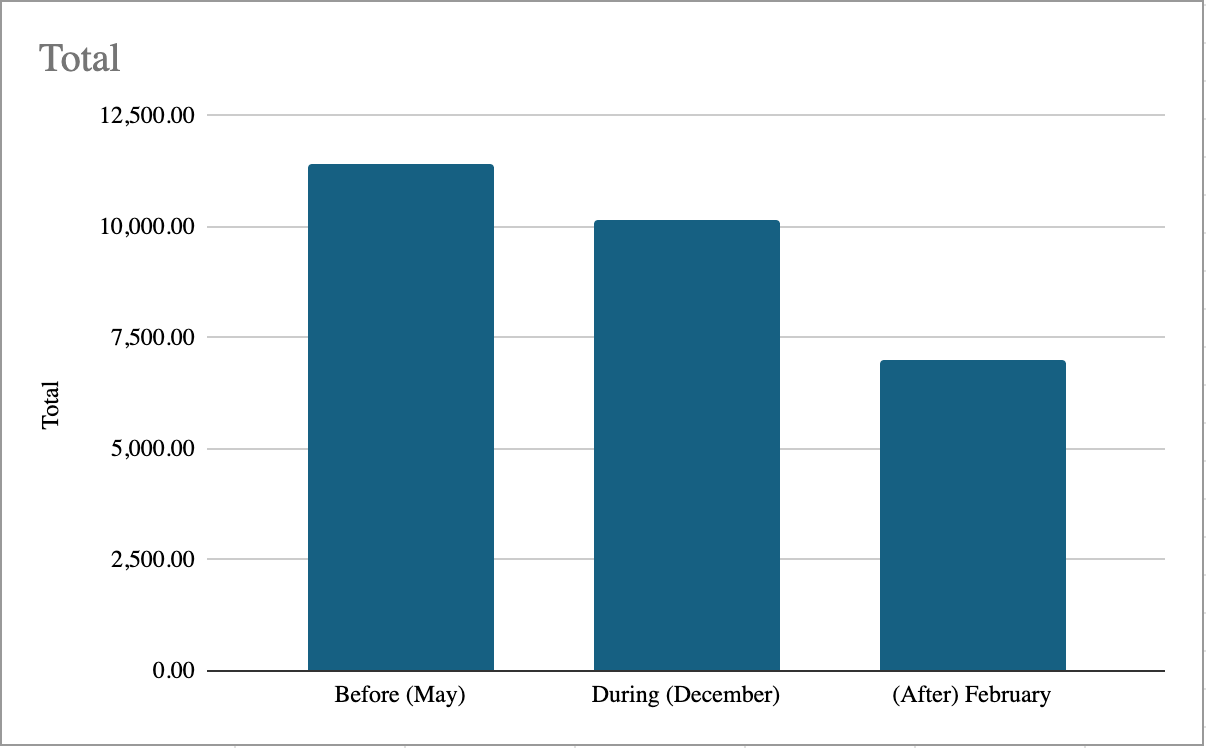 Tab. 2 - Total Cost Evolution by Stage
Tab. 2 - Total Cost Evolution by Stage
Cost evolution analysis
Observing the data presented in Table 2, it is evident that by the end of the migration, total costs had significantly decreased by 39% (approximately $4,500 per month), validating the effectiveness of the initial assumptions and decisions made during the project. This confirms that cost and resource optimization successfully aligned with the established objectives.
Additionally, despite maintaining a conservative approach, no significant additional costs negatively impacted the project. There is a gradual downward trend in EC2-related costs, while Fargate costs increased, albeit on a considerably smaller scale than EC2. This highlights Fargate's ability to allocate computing resources more efficiently, adapting to workload demands in an optimized manner.
If you’re interested in this project and need to implement something similar for your company or institution, contact us by clicking here. The coffee is on us ;) ☕️


Miguel Rizzo
Software Architect

